
GTC 2026 키노트와 차세대 AI 가속기, HBM4 메모리 모듈
AI 반도체 구조 이해하기 —
GTC 2026 발표로 본 HBM 기술 진화와 메모리 혁신 원리
엔비디아 GTC 2026에서 공개된 차세대 AI 가속기와 HBM4 로드맵 덕분에, 이제 AI 성능 경쟁은 **“GPU 코어 수”보다 “메모리 구조”**가 좌우하는 시대가 되었습니다. HBM3E·HBM4, 온칩 SRAM, 새로운 메모리 계층 구조까지 한 번에 정리해 드립니다.
· AI 반도체가 CPU·GPU·HBM·SRAM으로 나뉘는 구조 · HBM이 기존 DDR/그래픽 메모리와 다른 3D 적층·TSV 구조 · GTC 2026에서 삼성·SK·엔비디아가 내놓은 HBM3E·HBM4 로드맵 포인트 · LLM 학습·추론에서 HBM 용량·대역폭이 체감 속도를 어떻게 바꾸는지 · 개인 투자자·개발자가 체크해야 할 HBM 관련 키워드
1. AI 반도체 구조, 그림으로 먼저 잡기
AI 서버 안에는 CPU, GPU(또는 AI 가속기), 그리고 이들을 뒷받침하는 여러 계층의 메모리가 층층이 자리 잡고 있습니다. 가장 가까운 쪽에는 레지스터·캐시(SRAM), 그 다음이 HBM, 서버 전체를 공유하는 DDR 메모리가 붙는 식입니다.
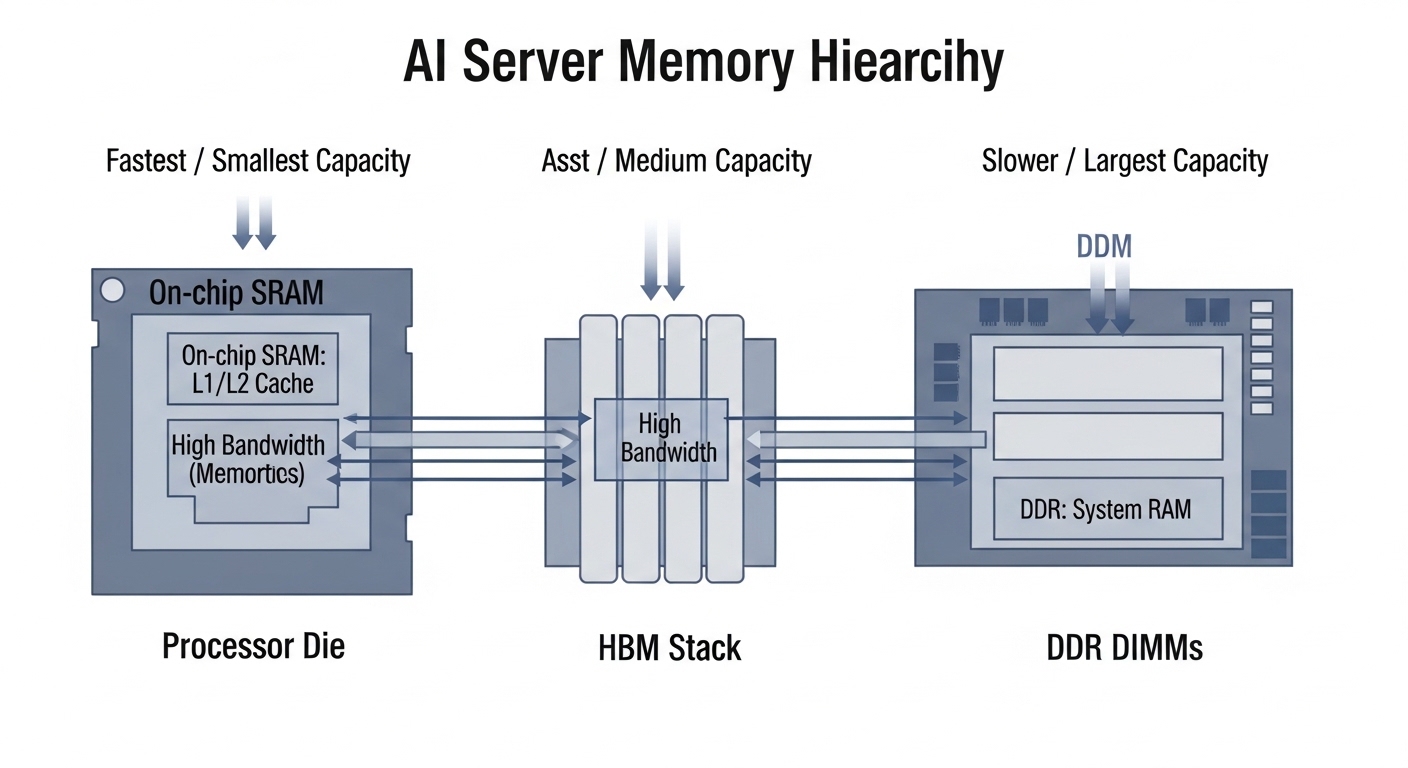
AI 서버의 메모리 계층 구조: 온칩 SRAM → HBM → DDR 순으로 배치
- 온칩 SRAM/캐시 – 속도는 가장 빠르지만 용량이 작고 칩 안에만 존재
- HBM – GPU 옆에 붙는 초고속 외부 메모리, LLM이 주로 올라가는 공간
- DDR 메모리 – 서버 전체가 공유하는 일반 메모리, 대용량 데이터를 저장
CPU·GPU는 “두뇌”라면, HBM은 “혈관” 역할을 합니다. 두뇌가 아무리 좋아도, 피(데이터)가 안 통하면 AI는 느려집니다.
2. HBM이 뭐길래 AI 반도체의 심장일까?
HBM(High Bandwidth Memory)은 여러 장의 DRAM 칩을 세로로 쌓고, 그 사이를 수직 배선(TSV)으로 관통해 연결한 메모리입니다. 데이터가 지나는 길을 넓히고 짧게 만들어, 같은 시간에 훨씬 많은 데이터를 주고받을 수 있게 설계된 구조입니다.
| 구분 | 일반 DDR 메모리 | HBM 메모리 |
|---|---|---|
| 구조 | 칩을 기판 위에 평면 배치 | 칩을 수직 3D 적층, TSV로 관통 연결 |
| 대역폭 | 수십 GB/s 수준 | 수백 GB/s ~ 1 TB/s 이상 |
| 소비전력 | 대역폭 대비 높음 | 대역폭 대비 낮음 (와트당 성능 우수) |
| 용도 | 일반 PC·서버 | AI 가속기, 고성능 GPU, HPC |
GTC 2026을 앞두고 공개된 자료들에 따르면, 2026년 기준 AI 서버용 HBM의 주력 제품은 여전히 HBM3E이며, 차세대 HBM4는 고급형 AI 가속기에 먼저 적용되며 비중을 점차 늘릴 것으로 전망됩니다.
3. GTC 2026에서 나온 HBM 진화 키워드
올해 GTC 2026에서는 엔비디아가 새로운 AI 가속기와 함께 HBM4 기반 플랫폼을 예고했고, 삼성전자·SK하이닉스는 HBM4·HBM4E, 6·7세대 HBM 로드맵을 발표하며 “AI 전용 메모리 경쟁”을 공식화했습니다.
- 삼성전자 – HBM4 중심의 메모리 로드맵과 엔비디아 GPU와의 호환성 강조
- SK하이닉스 – HBM4가 LLM 추론에서 메모리 병목과 지연 시간을 어떻게 줄이는지 발표
- 엔비디아 – 차세대 AI 가속기(예: 베라 루빈, Blackwell 계열)에서 HBM4를 주요 옵션으로 채택
· 주력: HBM3E (전체 출하량의 약 2/3 비중 예상) · 프리미엄: HBM4 (최상위 AI 가속기 중심으로 초기 탑재 후 점진 확대) · 공통 과제: 적층 높아질수록 수율·발열 관리 난이도↑
4. LLM 학습·추론 단계별로 보는 메모리 혁신 원리
대형 언어 모델(LLM)의 학습·추론은 간단히 말해 “엄청난 양의 행렬 연산”입니다. 이때 성능 병목은 GPU의 연산 능력보다, **파라미터와 활성값을 얼마나 빠르게 메모리에서 가져올 수 있느냐**에 의해 결정되는 경우가 많습니다.
- 학습(Learning) – 거대한 파라미터와 데이터셋을 반복적으로 읽고 쓰는 단계
- 추론 – Prefill – 프롬프트 전체를 한 번에 처리, HBM 용량·대역폭 의존도가 높음
- 추론 – Decode – 토큰을 한 개씩 생성하는 단계, 온칩 SRAM 기반 추론 전용칩이 각광
· 학습/프리필: 여전히 HBM 붙은 고성능 GPU가 주력 · 디코드: HBM 대신 온칩 SRAM 기반 추론 전용 칩이 GPU와 역할 분담 → HBM은 “사라지는 게 아니라” 메모리 계층이 더 세분화되는 방향
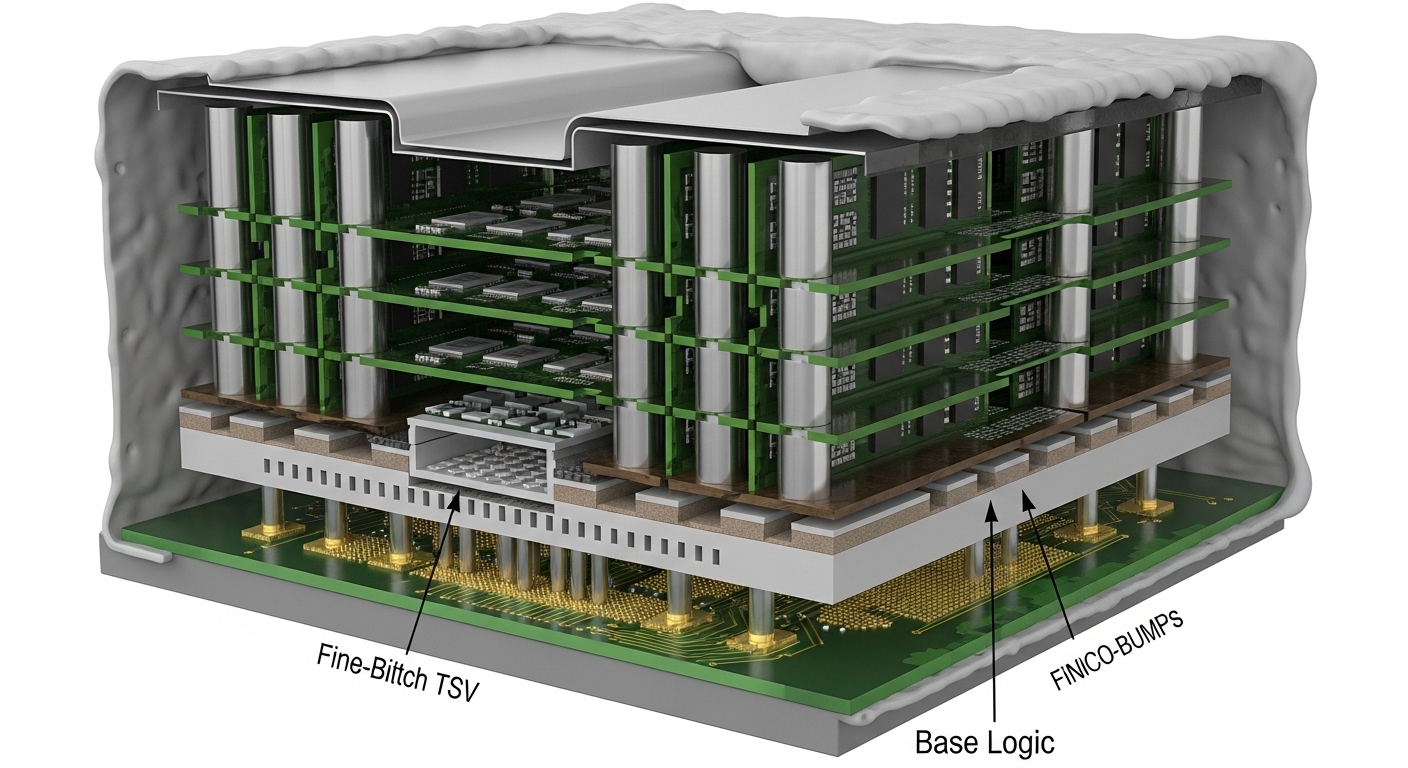
TSV로 연결된 HBM 3D 적층 구조 단면도 (스택+인터포저)
5. HBM 세대별 진화 포인트 (HBM2E → HBM3E → HBM4)
| 세대 | 대표 스펙(대역폭/스택당 용량) | 주요 용도 |
|---|---|---|
| HBM2E | 수백 GB/s, 수 GB 수준 | 초기 AI·HPC, 이전 세대 GPU |
| HBM3 / HBM3E | 1 TB/s 안팎, 24GB 이상 | 최신 AI 가속기, LLM 학습/추론 메인 |
| HBM4 (예정) | 대역폭·용량 모두 추가 확대, 더 높은 적층 | 차세대 데이터센터·최상위 AI 서버 |
증권사·업계 분석에 따르면, 2026년 HBM 전체 출하량에서 HBM3E 비중이 가장 크고, HBM4는 AI 슈퍼컴·프리미엄 클라우드 인스턴스를 중심으로 빠르게 비중을 늘려 갈 것으로 예상됩니다.
6. 투자·커리어 관점에서 HBM을 볼 때 체크할 것
- AI 가속기 스펙에서 “HBM 용량/스택 수/대역폭”이 어떻게 표기되는지
- HBM 공급사(삼성·SK·마이크론 등)와 엔비디아/클라우드 업체 간의 장기 공급 계약 뉴스
- TSV·패키징(2.5D, CoWoS 등) 생산 능력 증설 계획
- 온칩 SRAM 기반 추론 전용 칩 등장으로 인한 “역할 분담 구조” 변화
1) CPU/GPU 구조 기본 2) 메모리 계층 (SRAM·HBM·DDR) 3) HBM 적층·TSV·패키징 4) GTC·메모리 업체 로드맵 자료 정주행
7. 자주 나오는 질문 (FAQ)
Q1. HBM이 많으면 무조건 좋은 건가요?
같은 세대 기준으로 HBM 용량·대역폭이 늘어나면 LLM 처리량이 좋아지는 경향은 있지만, 칩 자체 성능·네트워크 구조와 함께 봐야 합니다.
Q2. HBM4가 나오면 HBM3E는 끝인가요?
아니요. 2026년에도 HBM3E가 출하량의 상당 비중을 차지할 것으로 예상되며, HBM4는 가장 높은 성능이 필요한 영역에서 먼저 쓰이게 됩니다.
Q3. 온칩 SRAM 기반 추론 칩이 HBM을 대체하나요?
대체라기보다는 역할 분담입니다. 프리필·학습은 여전히 HBM 기반 GPU가 강하고, 디코드 단계 일부를 SRAM 기반 칩이 분담하는 구조로 가는 흐름입니다.
Q4. 일반 개발자에게 중요한 포인트는?
직접 HBM을 만지지 않더라도, 사용 중인 클라우드 인스턴스의 GPU·HBM 스펙을 이해하면 비용 대비 성능을 더 잘 고를 수 있습니다.
Q5. 관련해서 더 공부하려면?
엔비디아 GTC 세션 영상, 삼성·SK 공식 기술 블로그, 그리고 HBM·AI 반도체를 다루는 기술 블로그를 함께 참고하는 것을 추천합니다.
'IT·디지털 가이드 > IT·뉴스' 카테고리의 다른 글
| "롤 MSI 2026 그룹 스테이지 완전 분석, 한국 대표팀 대진표·경쟁국 전력과 녹아웃 진출 가능성" (0) | 2026.05.06 |
|---|---|
| "안성재 모수 서울 와인 빈티지 논란 완벽 정리, 사과문 내용·논란 경위·와인 상식까지 한눈에 총정리" (0) | 2026.04.27 |
| "티핑포인트 완벽 가이드, 개념·유래·경제·사회·마케팅·환경 분야별 사례와 실전 적용법 총정리" (0) | 2026.04.27 |
| "메모리 혁명의 시작, 구글 터보퀀트가 AI 반도체·클라우드·스마트폰 산업에 미치는 파급효과 완전 분석" (0) | 2026.03.29 |
| 조립PC업체 컴마왕 대표 잠적설 확산과 영향 분석|소비자 피해 예방 가이드 (0) | 2025.11.07 |



